 Một dự án quét tài liệu đã tạo ra dung lượng 1.4TB LUN các hồ sơ cũ của tòa án. Glenn, quản lý IT cao cấp cho Tòa án Ohio, cho biết chỉ có 6% các file được truy cập trong năm qua và phần còn lại đáng ra không nên nằm trên một đĩa đắt tiền như Fibre Channel.
Một dự án quét tài liệu đã tạo ra dung lượng 1.4TB LUN các hồ sơ cũ của tòa án. Glenn, quản lý IT cao cấp cho Tòa án Ohio, cho biết chỉ có 6% các file được truy cập trong năm qua và phần còn lại đáng ra không nên nằm trên một đĩa đắt tiền như Fibre Channel.
Khó khăn của ông là làm sao xác định đúng 94% file không được truy nhập còn lại mà ông có thể chuyển đi tại bất kỳ thời gian nào đến các ổ đĩa Serial ATA chậm hơn và ít tốn kém hơn. Cuối cùng ông cũng đã có được phần mềm mà ông cần đó là công nghệ lưu trữ động - Dynamic Storage Technology (DST) - một phần của Novell Open Enterprise Server 2 - để tạo tập tin và tự động thực hiện các chính sách di chuyển file trên cơ sở khi file cuối cùng đã được truy nhập.
Sau một tuần điều chỉnh các cấu hình Glenn nói: "Nó cho một kết quả thật tuyệt vời ", ông đã giải phóng ít nhất một tá ổ đĩa Fibre Channel. Bằng cách giảm số lượng các tập tin hoạt động, ông cũng cắt giảm thời gian sao lưu hàng ngày của mình từ 14 giờ xuống 47 phút.
Việc cài đặt rất đơn giản, và cấu hình yêu cầu chỉ cần di chuyển các LUN cũ sang ổ cứng SATA, thực hiện đổi tên LUN, tạo ra một LUN nhỏ hơn trên Fibre Channel để thay thế nó, chỉ định các LUN mới làm volume chính (primary) và LUN cũ với vai trò shadow. "Sau đó, tôi bắt đầu thiết lập các quy tắc di chuyển," Glenn nói. Không phải trả thêm bất kỳ chi phí nào cho DST, ông nói thêm, nhưng ước tính tiết kiệm được 140.000$ nhờ sự giảm yêu cầu đối với các ổ đĩa và điện năng.
Glenn là một trong những người hưởng lợi đầu tiên của một công nghệ mới gọi là tự động phân tầng dữ liệu, nó tự động hóa không chỉ sự di chuyển dữ liệu mà còn có nhiệm vụ giám sát dữ liệu đang được sử dụng như thế nào và xác định những dữ liệu cần phải đưa vào dạng lưu trữ. Nhưng phân tầng tự động vẫn chưa trở thành phổ biến bởi vì mới chỉ có ít phân phối cung cấp công nghệ này và vẫn chưa được chứng minh có thể làm việc trong các môi trường giao dịch cao cấp chuyên sâu. Nó thường chỉ được sử dụng trong mảng bán lẻ hoặc file hệ thống hoặc hỗ trợ chỉ một số lượng hạn chế các giao thức hoặc topo lưu trữ. Nhưng đối với tổ chức có các nhu cầu đơn giản thì công cụ phân tầng tự động hiện nay là quá đủ tốt.
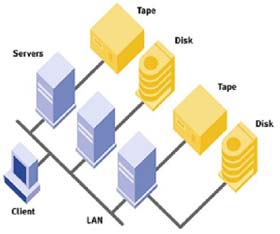
Làm thế nào để việc phân tầng trở nên tự động
"Tiering" có nghĩa là thực hiện di chuyển dữ liệu giữa các loại phương tiện lưu trữ khác nhau khi nhu cầu về nó tăng hoặc giảm. Di chuyển dữ liệu cũ, ít được truy cập hơn đến các thiết bị lưu trữ rẻ tiền hơn, tốc độ chậm hơn như các ổ đĩa SATA hoặc thậm chí là băng từ để làm giảm giá thành của phần cứng trong khi đặt dữ liệu mới, được truy nhập thường xuyên hơn, quan trọng hơn vào các ổ đĩa Fibre Channel đắt tiền hơn, tốc độ nhanh hơn thậm chí là các ổ đĩa trạng thái rắn (SSD) để tăng hiệu suất. Cuối cùng, tiến trình tự động hoá ngăn chặn nó sa lầy trong việc phân loại dữ liệu và thiết lập chính sách ảnh hưởng hiệu quả "phân tầng" như sự quản lý thông tin về chu kỳ tồn tại (life-cycle management -ILM).
Chuẩn bị, Cài đặt, Thực hiện?
Bạn nghĩ rằng tổ chức của mình đã sẵn sàng để khai thác những lợi ích của các công nghệ phân tầng dữ liệu tự động? Trước tiên hãy xem xét những vấn đề này trước:
- Nó có cung cấp kết hợp phân tầng cấp độ block và file mà bạn cần?
- Có thể ghi đè lên quá trình phân tầng tự động vì các lý do hiệu suất hoặc phục hồi dữ liệu?
- Nó có hỗ trợ các tính năng dự phòng hoặc de-duplication nếu bạn đang sử dụng chúng?
- Nó có hoặc sẽ hỗ trợ phân tầng Sub-LUN không?
- Nhà phân phối có cung cấp con đường phát triển cho sự tự động hóa hơn nữa không?
Các quản trị viên lưu trữ có thể di chuyển dữ liệu giữa các tầng, nhưng họ phải tự thực hiện quá trình bằng tay ít nhất là việc phân loại dữ liệu và tạo trước các chính sách phân tầng. Dù việc tạo ra chính sách vẫn còn cần thiết, nhưng hàng loạt các sản phẩm tự động mới nhất đã được thiết kế để làm giảm hoặc loại bỏ sự cần thiết việc sử dụng nhân viên để giám sát hệ thống lưu trữ và tìm kiếm các file cụ thể, do đó các volume và các khối (block) dữ liệu cần được phân tầng lại và di chuyển chúng bằng tay.
Các nhà quản lý CNTT trước tiên phải xem xét các tiêu chí mà phần mềm có thể thực hiện (chẳng hạn như dữ liệu thường xuyên được truy nhập như thế nào) và liệu nó có thể đánh giá và di chuyển các block hoặc các file độc lập thay vì chỉ di chuyển các volume hoặc các LUN lớn hơn. Do ít nhất là 10% block trong một volume có thể được kích hoạt đủ để biện minh cho sự cần thiết phải di chuyển tới thiết bị lưu trữ đắt tiền hơn, tốc độ nhanh hơn, nhưng bạn sẽ tiết kiệm được tiền nếu có thể di chuyển những khối này, đặc biệt là nếu bạn đang di chuyển đến các SSD đắt tiền.
Các yếu tố khác để xem xét bao gồm cách thức phần mềm có thể nhanh chóng phát hiện và phản ứng với những thay đổi trong việc sử dụng dữ liệu, và liệu các quản trị viên có thể ghi đè lên sự phân tầng tự động nếu nó ảnh hưởng đến hiệu suất ứng dụng. Các quản trị viên cũng có thể sử dụng nó để dự đoán khi dữ liệu chắc chắn cần thiết (ví dụ như các file kế toán cho việc quyết toán quý), do đó, phần mềm phân tầng có thể cập nhật nó trước thời hạn. Cuối cùng, các quản trị viên cần phải quyết định cách thức mà họ cảm thấy thoải mái để nhượng quyền kiểm soát cho một công cụ tự động.
Trong khi các cửa hàng IT đã vật lộn trong nhiều năm để thực hiện ILM thì một số người đã từng sử dụng phân tầng dữ liệu tự động nói rằng họ vẫn đang nhận được những lợi ích đáng kể với phần mềm hiện đang có sẵn.
Sandee Sprang, giám đốc CNTT cho văn phòng luật sư trưởng của Nam Carolina đã thiết lập một mạng lưu trữ vùng với phân tầng tự động bằng cách sử phần mềm Data Progression của Compellent Technologies Inc khoảng 5 năm trước đây, bởi vì bà không có nhân viên "để phân loại loại hồ sơ cần thiết cho việc lưu trữ hiệu quả nhất và truy cập nhanh ". Việc thiết lập các chính sách cho hệ thống Compellent mất khoảng bốn giờ, và "những lợi ích mà nó mang lại hoàn toàn có thể cảm nhận được bằng giác quan", bà nói rằng thời gian quản lý lưu trữ đã giảm nhiều từ 24 giờ một tuần xuống hai giờ một tuần.
Phân tầng cấp độ block của Compellent cũng giúp tối đa hóa việc sử dụng đĩa, bà nói thêm, và nó "không có nghĩa là toàn bộ tập tin được di chuyển lên xuống các tầng" – mà "cái di chuyển chỉ là một bản sơ yếu lý lịch bạn đang truy cập hoặc một bảng điểm từ 15 năm trước đây."
Brian Nielsen, kiến trúc sư công nghệ hệ thống tại Salk Institute's Computational Neurobiology Laboratory, làm việc trong một môi trường máy tính khoa học với khối lượng công việc biến đổi lớn bởi vậy cần các phân tích thời gian thực và retiering được cung cấp bởi các thiết bị lưu trữ liên kết mạng của Avere Systems Inc. Đầu tiên chỉ là dùng thử, và cuối cùng là mua các thiết bị chuyên dụng, ông nói, nó là một thách thức đối với việc chuyển dữ liệu và việc xác định được những dữ liệu nào cần di chuyển.
Không giống như các sản phẩm ILM trước đó, việc phân tầng lại dữ liệu được thực hiện một cách rời rạc không thường xuyên và chỉ dựa vào lần truy nhập cuối cùng, hệ thống Avere có thể "thực hiện ghi chép cho nhiều file thuộc tính I/O khác nhau hoặc tầng [dữ liệu] động " khi các yêu cầu ứng dụng thay đổi, Nielsen nói.
Brian Bosserman, giám đốc điều hành hệ thống và mạng tại Foster Pepper PLLC, một công ty luật ở Seattle, đang thử nghiệm với công nghệ phân tầng lưu trữ tự động hoàn toàn (FAST) của EMC Corp. trên các Celerra EMC NS-480 chạy tại các văn phòng của công ty ở Spokane và Seattle. Ông ước tính rằng nó sẽ tiết kiệm được 10% thời gian hiện đang dành cho việc giám sát các nhu cầu lưu trữ của máy chủ, sau đó là việc lên kế hoạch và thực hiện phân tầng lại của các máy ảo trong số đó. Với FAST, ông nói, hy vọng sẽ để Rainfinity File Management Appliance của EMC làm việc giám sát và di chuyển "dựa trên các chính sách mà tôi cung cấp cho nó ".
Việc cài đặt FAST "rất đơn giản," Bosserman nói. "Nó như là một thiết bị VMware [ảo]. Tôi chỉ việc nhập các thiết bị FAST, bắt đầu như một máy tính UNIX, sau đó thâm nhập vào nó thông qua giao diện web và thực hiện quản lý, cài đặt nó từ đó."
Tuy nhiên, phân tầng dữ liệu tự động đòi hỏi trước một số thao tác như việc phân lớp dữ liệu và thiết lập các chính sách để xác định khi nào các dạng dữ liệu chắc chắn cần thiết cần được di chuyển (dựa vào độ tuổi của dữ liệu, hiệu suất ứng dụng, hoặc các yêu cầu pháp lý và quy định). Một số người nói rằng tất cả các công việc trên đã làm tê liệt các phương pháp phân tầng trước đó như ILM. Nhưng ít nhất một người sử dụng lớn - Intel Corp CIO Diane Bryant – đang đặt một quá trình ILM chính thức vào nơi mà phân tầng tự động đang được nghiên cứu trước đó. Bryant đã bắt đầu một nỗ lực với ILM vào cuối năm ngoái để phải cắt giảm sự tăng trưởng đến 35% hàng năm của Intel về nhu cầu lưu trữ thiết yếu, và khoảng 40% dữ liệu có cấu trúc và 30% dữ liệu không có cấu trúc của công ty hiện được quản lý bởi ILM.
Sanford Coker, lãnh đạo bộ phận Unix và là quản trị viên Unix cao cấp tại trường Cao đẳng Y khoa Weill Cornell, bắt đầu sử dụng Policy Advisor của 3Par Inc trong môi trường kiểm tra và phát triển của ông. Việc cài đặt rất dễ dàng, ông nói, và việc tạo ra mỗi chính sách chỉ mất khoảng 30 phút, mặc dù việc hiệu chỉnh chúng sao cho hiệu suất tối ưu phải mất một tuần hoặc lâu hơn. Ông nói rằng theo ước tính thì có thể cắt giảm khoảng 25% việc sử dụng đĩa Fibre Channel bằng cách di chuyển dữ liệu đến các đĩa SATA dung lượng cao hơn, ít tốn kém hơn.
Tiếp theo sẽ là gì?
Khi hoàn thiện, phân tầng dữ liệu tự động có thể giúp chấp nhận sử dụng ổ đĩa SSD cho lưu trữ dữ liệu, bởi vì nó sẽ giúp các quản trị viên điều chỉnh việc phân tầng đủ để đảm bảo rằng họ đang nhận được lợi ích tối đa với hiệu suất cao nhất từ những phương tiện lưu trữ đắt tiền nhất. Nhưng hiện nay, theo các quản trị viên lưu trữ, các nhà cung cấp và các nhà phân tích, ổ đĩa SSD là quá đắt đối với hầu hết những người sử dụng chủ đạo.
Reichman nói, nó vẫn còn nhiều hiệu quả về giá trong không gian thương mại đối với hiệu suất nhờ các ổ đĩa "short-stroking" (đây là loại ổ đĩa chỉ cho phép ghi dữ liệu lên các sector bên ngoài của bề mặt đĩa) – như việc cố ý chỉ sử dụng một phần dung lượng các ổ đĩa để cải thiện hiệu suất của chúng. Giá cho các khả năng phân tầng nằm từ miễn phí (cho phần mềm đã được bao gồm trong các sản phẩm có sẵn hiện nay) cho đến hơn 50.000 $ cho các hệ thống như FCN 2300 của Avere. Người dùng, tất nhiên, cũng là một yếu tố đối với chi phí cho việc phân loại dữ liệu và tạo ra các chính sách phân tầng.
Các nhà phân phối lớn như EMC cũng đang làm việc để phân tầng dữ liệu tự động trở thành "ứng dụng nhận thức", nghĩa là phần mềm sẽ hiểu được các nhu cầu I/O cũng như các mẫu sử dụng khác của các ứng dụng phổ biến và tự động phân tầng lại để đáp ứng các nhu cầu này. Do đó khả năng tương tác sẽ đòi hỏi các tiêu chuẩn đối với thông tin về dữ liệu đang được phân tầng lại. Một trong số đó là tiêu chuẩn siêu dữ liệu đang được phát triển bởi Hiệp hội Công Nghiệp Lưu Trữ Mạng (Storage Networking Industry Association).
Theo QuanTriMang